


According to the International Data Corporation, an estimated 59 zettabytes of data have been generated, captured, duplicated, and utilized in 2020. It’s a significant amount of data and fills almost one trillion 64-gigabyte hard drives. AI has made data the new oil, but only a few are striking it rich. In spite of this, many people are making their fuel — that’s inexpensive and effective. That fuel is known as synthetic data.
Synthetic data is artificially generated data that mimics real-world data but with a difference. Unlike real data, synthetic data is free from privacy and security concerns, making it safe for researchers, organizations, and developers to use for various purposes.
Let’s get to know About Synthetic Data in detail!
What is Synthetic Data?
Synthetic data can be defined as data that isn’t based on real-world events or phenomena but rather is generated by a computer program. First, the algorithm learns the sample data’s patterns, correlations, and statistical properties. Once trained, the generator can create statistically identical, synthetic data.

What’s amazing about synthetic data is that if it’s run through a model or used to build or test an application, it performs as that real-world data would. Whether in computer games like flight simulators or scientific simulations of everything from atoms to galaxies, synthetic data has been around us for decades.

Are There Any Varieties in Synthetic Data?
Yes! synthetic data contain a few variations like:
- Text Data: synthetic data could be in the form of artificially generated text in NLP applications.
- Tabular Data: this kind of synthetic data contains artificially generated data that exactly looks like real-life data blogs or tables used for regression or classification tasks.
- Media: it could be synthetic images, videos, or music that can be used in computer vision applications.
What is a Synthetic Dataset, and Why is it needed?
The synthetic dataset is a perfect proxy for real since it contains the same insights and correlations.
In simpler terms, a synthetic dataset contains data generated through AI algorithms instead of real-world data. Synthetic datasets are usually generated for quality assurance and software testing. Also, the synthetic dataset’s ultimate goal is to be versatile and robust enough to be useful for training machine learning models.
How Is Synthetic Data Created?
It’s all thanks to those deep generative algorithms that use existing data as a model to learn all the correlations, stats, and structures. Then, once they’ve been trained, they can just crank out new data like the original data they learned from.
Methods For Generating Synthetic Data
Let’s take a look at the most common methods for generating synthetic data, starting with the most basic approach:
-
Drawing Numbers From a Distribution
Compared to popular machine learning techniques, this one is a popular technique for generating synthetic data — it simply draws sample numbers from a distribution. And since this approach doesn’t capture insights into real-world data, it can generate a curve based loosely on real-world data.
-
Agent-Based Modeling
This simulation technique involves creating individual agents that interact with one another. These agents can be cells, people, or even computer programs. Interactions between these agents are examined in a complex system.
-
Generative Models
Generative models are the most advanced method to generate synthetic data.
Typically, deep learning generates synthetic data with variational autoencoders (VAE) or generative adversarial networks (GAN). VAEs are unsupervised machine learning models that make use of encoders and decoders. When it comes to GAN models, both networks compete with each other. The generator generates synthetic data, while the second network discriminator operates by comparing the generated data with a real dataset while analyzing the fake dataset.
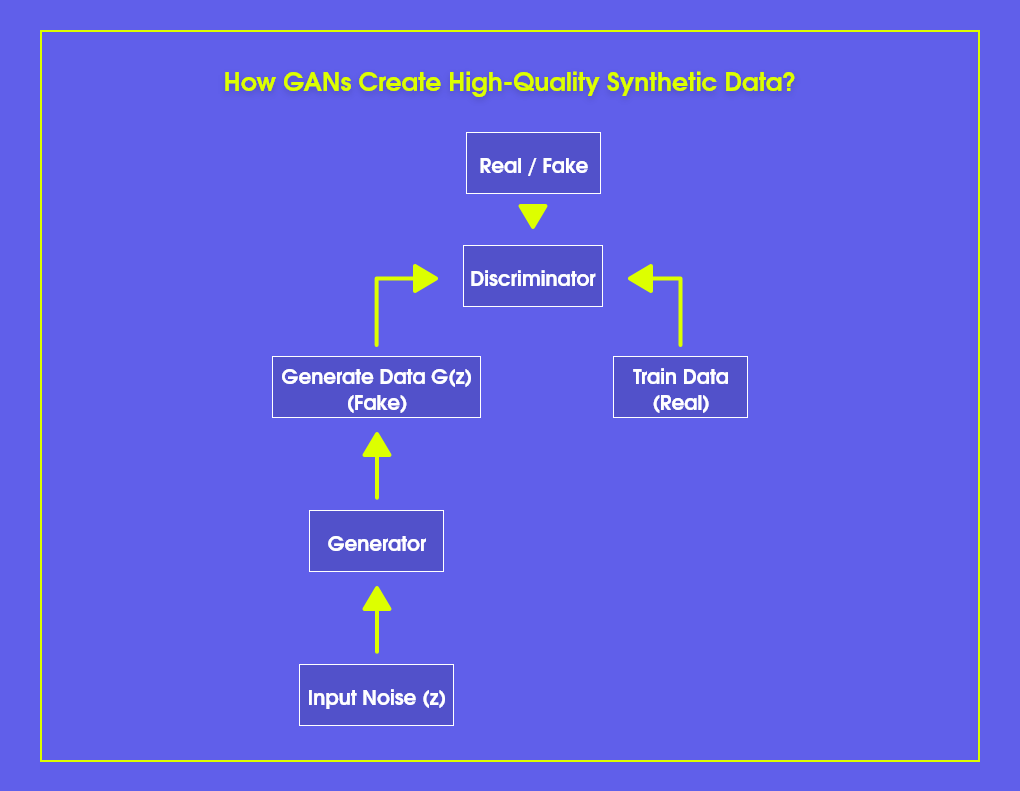
While generating synthetic data, it’s crucial to prevent overfitting of the original data. AI algorithms can be over-smart, sometimes, and accidentally creates original data points. That’s why a proper quality check-n-balance is necessary. Open-source data generators typically need high maintenance, while commercial solutions are more robust, offering quality-controlled options.
Types of Synthetic Data Revolutionizing the Landscape of Data Science
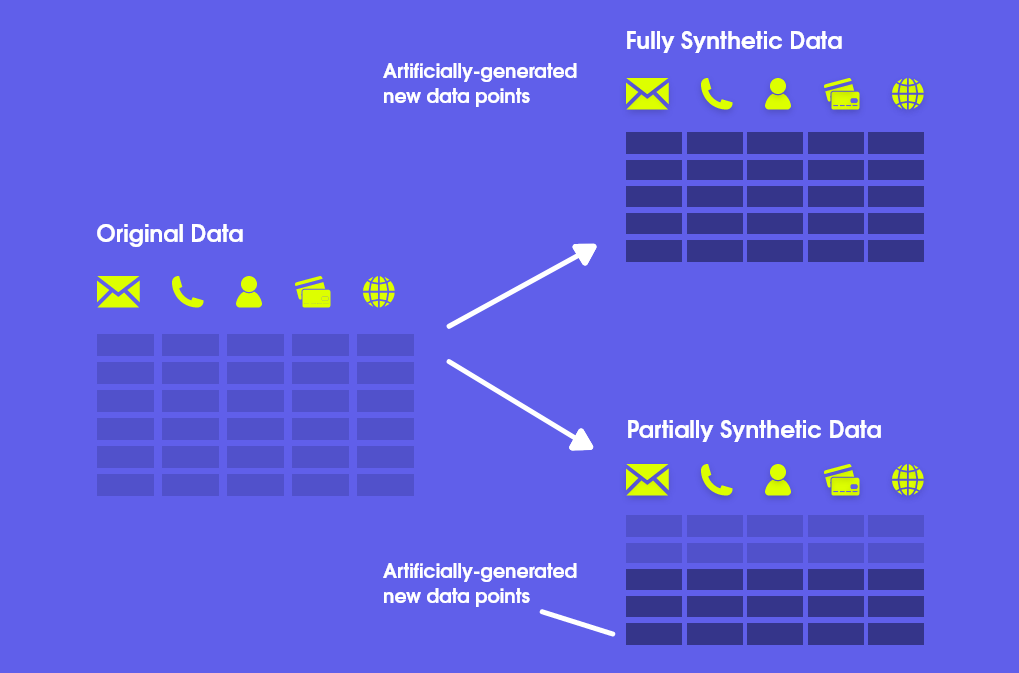
Data scientists use synthetic data to keep sensitive information safe while keeping all the important stats from real data. Typically, there are three major types of Synthetic data:
Fully Synthetic
The data-generating program identifies and analyzes real-world data characteristics, including feature density, to arrive at realistic parameter estimations. It then generates synthetic data based on these estimated feature densities or using generative methods. As its name suggests, its a fully synthetic data and retains nothing from the original data. Since no actual data is used, this type of synthetic data offers robust privacy protection, albeit at the cost of reduced data accuracy and truthfulness.
Partially Synthetic
Using both model-based and imputation methods, data scientists can produce partially synthetic data that retains some of the original data’s characteristics. This technique fills in missing data and allows for the permutation of unstructured data to add even more diversity. Allows to replace selected features with entirely new, yet still realistic, values.
And when it comes to structured data with privacy restrictions, partially synthetic data is often used to protect high-risk or privacy-sensitive information by obscuring it behind a mask of synthetic values.
Hybrid
It offers the benefits of both partially and fully synthetic data while offering a high level of utility and privacy protection. However, the only snag this type of synthetic data contains is takes longer processing time and memory.
The Game-changing Industry Use Cases For Synthetic Data
Being an industry-agnostic solution, there’s no industry you can’t use synthetic data in, from finance to healthcare, insurance to telecom. Chatbot development, self-driving cars, and dialog processing are the most popular synthetic data use cases, with many more coming.

It is predicted that 20% of all test data for consumer-facing use cases will be synthetically generated by 2025.– Gartner
1. Banking and Finance
In the business world, departments often operate independently, separating data providers from those who utilize the data. However, this outdated work structure makes data implementation tough. Furthermore, increasing demands for personalization and privacy have heightened the importance of cybersecurity.
Synthetic data has the potential to address these and other pressing concerns. Moreover, for global banking, McKinsey estimates that AI technologies could potentially deliver up to $1 trillion of additional value each year. Also, American Express & J.P. Morgan use synthetic financial data to improve fraud detection.
2. Telecommunication
Telecos have to tackle multiple challenges at a time. For example, decreasing profits, strict regulations, and increasing customer demands. Moreover, there’s a high demand to share data seamlessly in the telecom landscape. With synthetic data, you can easily access GDPR-compliant alternatives. By doing so, operational costs can be reduced further, and revenue can be generated in new ways for the telecom industry.
3. Healthcare
The use of synthetic data is great for creating models and datasets to test health conditions without actual data. In medical imaging, synthetic data trains AI models while taking special care of patient privacy. Moreover, the latest trend indicates that synthetic data could be employed to predict disease trends.
4. Automotive Industry
Waymo, the well-known self-driving taxi company, employs synthetic data to train its autonomous vehicles. Its proprietary Chauffernet deep recurrent neural network can detect favorable and unfavorable road conditions. The cabs are trained on a combination of labeled synthetic and real-world data to ensure passenger safety. This training data also enables the vehicles to follow traffic regulations and identify objects on the road.
5. Manufacturing
Manufacturing Industry is leveraging synthetic data for predictive maintenance and quality control. Also, one of the best use cases of synthetic data in the manufacturing landscape is creating realistic, artificial consumer product group (CPG) datasets that could be used to generate and test various supply chain scenarios.
6. E-commerce
From improving price structures to demand to forecast, assort planning to inventory management, and synthetic data helps e-commerce businesses to train their machine learning algorithms on large training datasets generated with synthetic data. Also, the business has no access to large datasets and has privacy concerns; synthetic data can be a solution.
7. Agriculture
Synthetic data helps CV applications that assist agriculture professionals in predicting accurate crop yield, crop disease detection, seed, fruit, or flower identification, and plant growth. Moreover, you can create a digital twin of a field trial to test variables such as soil types or weather conditions. These variables will help you check whether these conditions would be successful in real-world field trials.
8. Social Media
Social media platforms and networks are filled with fake news, harassment, and political propaganda. In such a situation, testing with synthetic data ensures that content filters are flexible enough, can detect fake news, and deal with cyber attacks.
However, it doesn’t even matter whether the data is real or synthetic. What matters—are the characteristics and patterns the data carries inside. In addition to optimizing and enriching your data, synthetic data unlocks several key benefits. The Quality, Balance, and Bias of data.
Data Without Limits: Exploring the Advantages of Synthetic Data
Synthetic data has quite a few benefits that make it a popular choice in various industries. Here are some of the key advanatges of synthetic data:
-
Increased Data Quality
Besides being tough and expensive to access, real-world data also carries errors, inaccuracies, and biases on the top. These factors badly impact the quality of your machine learning model since it is trained in that error-prone data. Nevertheless, synthetic data offers you high-quality and error-free data.
-
Cost-effectiveness
Generating synthetic data is usually much cheaper than collecting and annotating real-world data. That’s especially true for large datasets, which can be time-consuming and expensive to gather manually.
-
Data Privacy
In some cases, it may not be possible or ethical to use real-world data due to privacy concerns. Synthetic data provides a way to generate realistic datasets without compromising sensitive information.
-
Control Over Data Characteristics
When generating synthetic data, you have complete control over the data’s characteristics, such as distribution, noise level, and correlation between features. It allows you to create datasets tailored to your specific needs and can improve the performance of machine learning models.
-
Scalability
Generating large amounts of synthetic data is often much easier and faster than collecting and labeling real-world data. That makes it a valuable tool for training and testing machine learning models, especially in applications requiring large amounts of data.
-
Faster Time-to-Market
Synthetic data can also help businesses market their products and services faster. Using synthetic data to train machine learning models, businesses can accelerate the development and testing process, reducing the time and resources needed to bring a new product or service to market.
For example, synthetic data can be used in the automotive industry to train self-driving car models, allowing manufacturers to get their products on the road faster and more safely.
Overall, synthetic data provides a cost-effective, privacy-preserving, and highly customizable alternative to real-world data that can be used to improve the performance of machine learning models.
What does the Future Hold for Synthetic Data?
Synthetic data is faster, more flexible, and more scalable than real-world data. You can also use it to generate data that doesn’t exist in the real world by adjusting parameters.
So overall, the future of synthetic data is looking very promising. As businesses collect more data and seek ways to derive insights and train AI models, synthetic data will become an increasingly important tool. Whether it’s improving accuracy, accelerating time-to-market, or preserving data privacy, synthetic data can be a game-changer for businesses and industries in the future.



